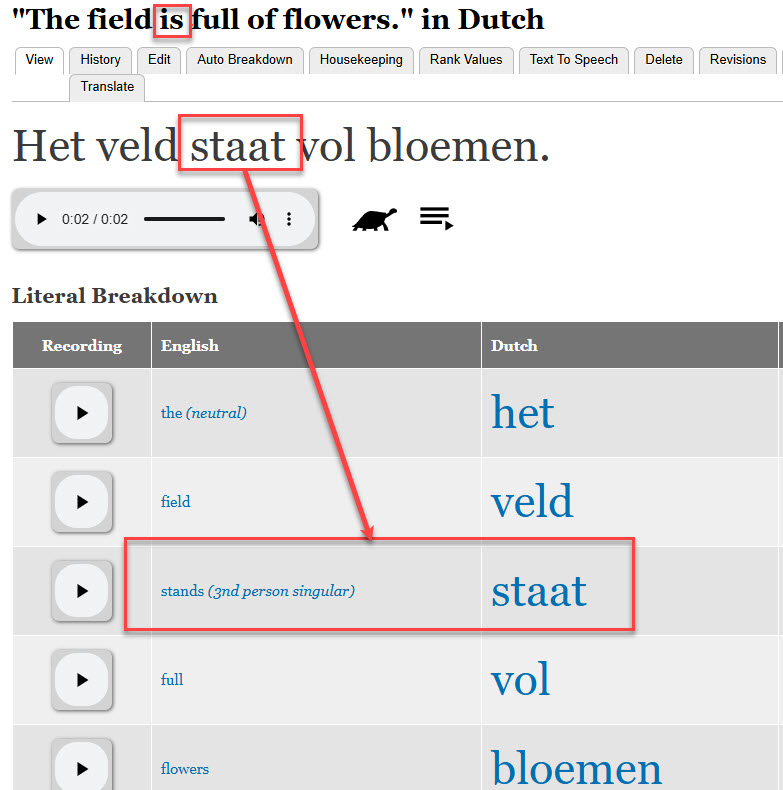
One of the other common mistakes the automatic content creation often makes is that it tries to be too helpful in creating entries which are incorrect in the literal breakdown.
For example, let's take the following, "The field is full off flowers". The entry "is" (English) meaning "staat" has been created. At first glance that looks correct.
However, let's check a bit deeper. We know that "is" comes from the verb "to be" (I am, you are, he is...). How about "staat"?
I ask ChatGPT:
"explain in detail the dutch: Het veld staat vol bloemen."
and this is what the answer back includes:

So, we see that "staat" comes from the "staan" meaning "to stand", not from the verb "to be" at all.
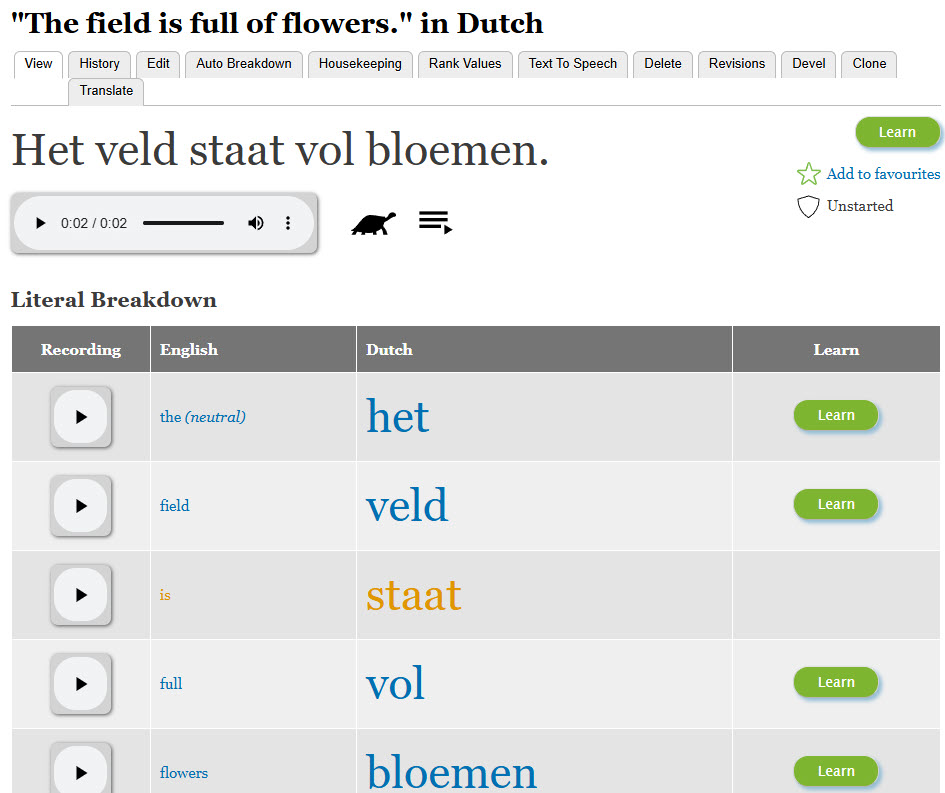
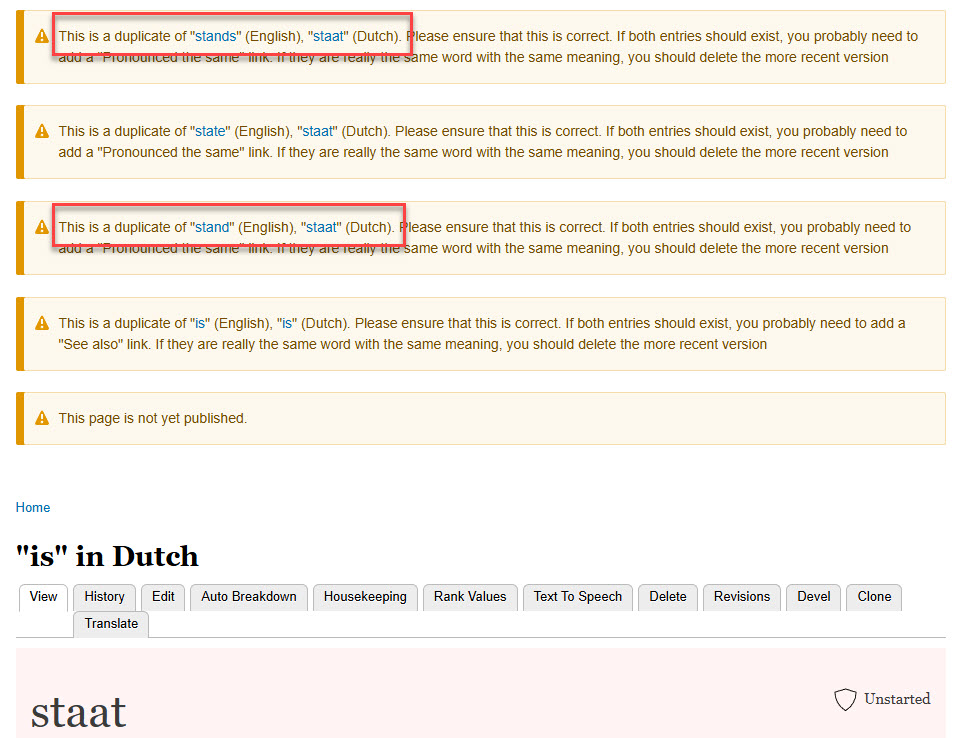
When we look at the entry "is" we see that the entries already existing are translated as "stands" or "stand". Therefore, we should change the "The field is full of flowers" example so that it uses the existing "staat" meaning "stands" (3rd person singular), and then we can delete this incorrect "is" meaning "staat" entry.
The end result is as follows. The original phrase uses "is" but the literal breakdown uses the more literal "stands":